工作
提出了一种新的矢量协处理器,在不牺牲性能的情况下满足时间关键应用的需求。
- 提出了一个在SystemVerilog中实现的可预测时间的32位矢量协处理器,它完全符合RISC-V矢量扩展的0.10版本草案(开源工程中已经是1.0版本)。所有整数和定点矢量算术指令,以及规范中描述的矢量约简、掩码和置换指令,都已实现。并且开源在https://github.com/vproc/vicuna.
- 将提出的协处理器与开源RISC-V核心Ibex集成在一起,并表明这种组合处理系统没有timing anomalies。
- 我们在数据并行基准应用程序上评估了我们的设计的有效性能,对于计算密集型任务的效率达到90%以上。
架构
Vicuna是一个高度可配置的,完全定时可预测的32位顺序矢量协处理器,实现RISC-V矢量扩展的整数和定点指令。
使用32位顺序RISC-V核心Ibex作为主处理器,它最初是作为PULP平台的一部分开发的,名为Zero-riscy。Ibex只有两级流水线:取指阶段以及译码和执行的组合,Ibex执行所有非向量指令。
Vicuna通过协处理器接口与ibex连接,通过协处理器接口ibex可以将指令字和寄存器内容从转发到协处理器,并可以从读取vicuna中读取结果。如果指令的主操作码表明是矢量指令,则通过该接口将指令字转发到矢量核。除了指令字之外,来自ibex的寄存器堆的的标量操作数也被传输到vicuna,因为一些使用标量寄存器作为源寄存器的矢量指令需要这些操作数,例如,矢量加法的一种变体,它向矢量的每个元素添加一个标量值,或者是从标量寄存器读取内存地址的矢量加载和存储指令。
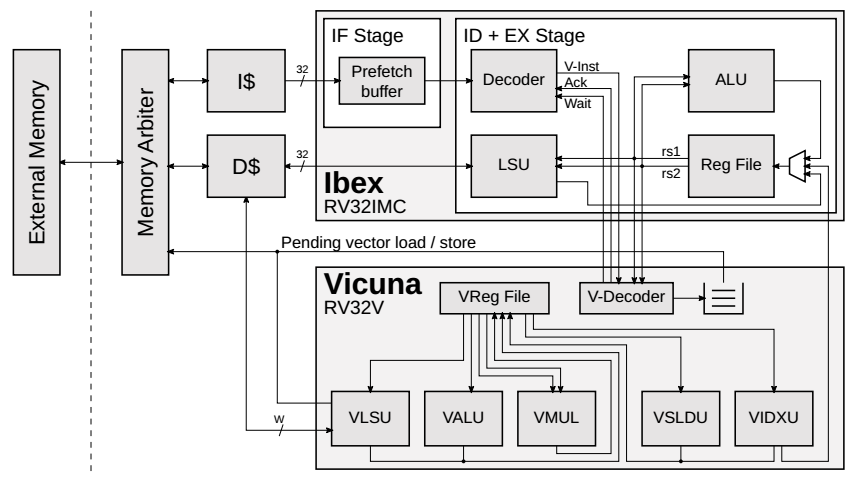
Vicuna包含一个矢量指令译码器,该解码器解析并确认有效的矢量指令。当译码器成功地译码出了一条矢量指令,他将声明指令被接收,并通知主内核是否需要等待标量结果。如果矢量指令不产生标量结果,而只是写入矢量寄存器或内存,则主核可以在协处理器上并行执行矢量指令的同时继续执行其他指令。然而,当一个矢量指令写回主核中的寄存器时,主核就会停止运行,直到协处理器完成该指令。只有四个RISC-V矢量指令产生标量结果。因此这种情况很少发生。解码后的矢量指令被放置在指令队列中,等待在矢量内核的functional unit执行。Vicuna是一个严格按顺序的协处理器:指令队列中的矢量指令按照从主核接收到的顺序被发射。只要没有数据冒险并且相应的功能单元可用,就会发射这条矢量指令。
作者的主要目标是设计一个 timing-predictable的矢量处理器,因此作者避免了任何导致timing anomalies的特征,例如选择功能单元的运行时决策。ibex和vicuna共享一个采用LRU替换策略的2路dcache,并且优先响应向量核心的访问。一旦一条指令被某个functional unit上执行,它就会在一个固定的时间内完成,这个时间只取决于指令类型、单元的吞吐量和当前的矢量长度设置。对于矢量加载和存储,执行时间还取决于数据缓存的状态,这是时间可变性的唯一来源。但是,对于标量和矢量内存操作,通过延迟主核中缓存丢失后的任何访问,直到挂起的矢量加载和存储完成,可以保证顺序内存访问。值得注意的是矢量加载和存储指令会使主核停滞有限且确定的数个周期,因为在主核停滞时,没有额外的矢量指令可以转发到矢量核。由于Ibex采用简单的两级流水线,两级流水线之间的内存访问冲突是同时可见的。在这种情况下,内存仲裁器通过优先服务数据访问来保持严格的顺序。
Vicuna由几个专门的functional units组成,每个functional unit负责执行RISC-V矢量指令的一个子集,从而允许同时执行多条指令。执行单元不会一次处理整个向量寄存器。相反,在每个时钟周期中,只处理矢量寄存器的一部分,包含被并行处理的几个元素。大多数array processors和一些vector processors被组织在lane中。每个通道复制一次处理一个矢量元素所需的计算资源。在这样的系统中,lane的数量决定了可以并行处理的元素的数量,而不考虑操作的类型。
相比之下,Vicuna为不同的指令类型使用专用的执行单元,每个指令类型一次处理多个元素。通过增加每个单元的数据路径宽度,可以为每个单元单独配置吞吐量,从而提高频繁使用的操作的性能。
- A Vector Load and Store Unit (VLSU) interfaces the memory and implements the vector memory access instructions.
- The Vector Arithmetic and Logical Unit (VALU) executes most of the arithmetic and logical vector instructions.
- A dedicated Vector Multiplier (VMUL) is used for vector multiplications.
- The Vector Slide Unit (VSLDU) handles vector slide instructions that move all vector elements up or down that vector synchronously.
- A Vector Indexing Unit (VIDXU) takes care of the indexing vector instructions. It is the only unit capable of writing back to a scalar register in the main core.
VALU使用可分割加法器进行加减运算,该加法器由一系列8位加法器组成,其进位链可以级联,以实现更广泛的操作。四个级联的8位加法器执行四个8位、两个16位或一个32位操作,具体取决于当前元素的宽度。类似地,VMUL单元使用可分割的乘法器在同一硬件上执行8位、16位和32位乘法。可断裂加法器和乘法器通常用于基于fpga的矢量处理器。从一个较大的矢量寄存器中选择一个相对较大的子字会消耗大量的逻辑资源。因此,我们避免了所有功能单元的子字选择逻辑与常规向量寄存器访问模式。这些单元从移位寄存器中读取整个向量源寄存器:
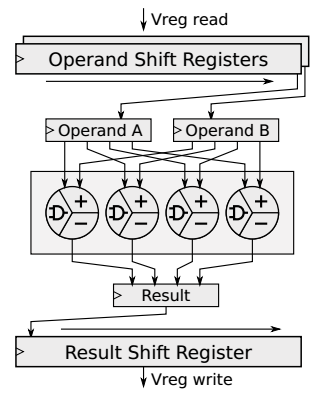
根据unit每个周期可以同时处理的元素数量进行移位,从而使矢量源寄存器的下一个元素可用于流水线的处理。类似地,处理结果被聚合到另一个移位寄存器中,该移位寄存器保存计算结果,直到整个向量完成计算,然后将整个向量寄存器写回寄存器堆。移位寄存器所消耗的组合逻辑资源比基于索引的子字选择逻辑所需要的逻辑资源要少。
Vicuna的矢量寄存器文件包含32个可配置宽度的矢量寄存器。为了支持执行单元的并行操作并获取其结果,矢量寄存器堆需要多个读写端口。我们利用functional unit的移位寄存器,它一次获取整个向量寄存器的值并在存储整个寄存器之前累积结果,通过这种方式实现读写端口的复用。每个功能单元都有一个专用的读端口,用于顺序地获取操作数寄存器,将它们存储在移位寄存器中,并在移位寄存器中迭代地使用它们。这在获取两个操作数寄存器时增加了一个额外的周期,但避免了在每个单元上需要两个读端口,但VMUL是例外具有两个读端口,用来支持使用三个操作数的融合乘加指令。